Jen-Yuan (Joy) HuangHello! I am a Master's student at the School of Intelligence Science and Technology of Peking University, where I am supervised by Professor Tong Lin. My research focuses on Generative Modeling, particularly in computer vision, with the long-term goal of building models that can effectively represent and understand our physical world. Currently, I am a remote research intern at Harvard University, working on compositional generalization under the supervision of Professor Yilun Du. Previously, I collaborated with with Professor Huan Wang at Westlake University on text-to-image diffusion model compression. To bridge the gap between research and real-world applications, I have gained industry experience as a student researcher at Tencent Hunyuan, Xiaohongshu, and SenseTime. I am also an active contributor to the open-source community as a member of the InstantX Team, where I develop AI-generated content (AIGC) models. I received my Bachelor's degree in Industrial Engineering from Nanjing University, with a specialization in optimization and operation research. During my undergraduate studies, I had the opportunity to work closely with Professor Xiaopeng Luo. |

|
Publications |
 
|
InstantIR: Blind Image Restoration with Instant Generative ReferenceJen-Yuan Huang, Haofan Wang, Qixun Wang, Xu Bai, Hao Ai, Peng Xing, Jen-Tse Huang arXiv, 2024 arXiv / demo / website / code In this work, we implement an auto-regressive image restoration process utilizing pre-trained text-to-image diffusion model. At each denoising step, we first generate a restoration reference from current diffusion latent, which is then used to condition the sub-sequent diffusion step. |

|
Long-Text-to-Image Generation via Compositional Prompt DecompositionJen-Yuan Huang, Tong Lin, Yilun Du under review, 2025 We develop an unsupervised prompt decomposition module, which decompose paragraph-long text prompt into manageable sub-prompts. A pre-trained text-to-image diffusion model process these sub-prompts in parallel with the outputs merged into a composed prediction through product-of-expert sampling. |

|
CSGO: Content-Style Composition in Text-to-Image GenerationPeng Xing, Haofan Wang, Yanpeng Sun, Qixun Wang, Xu Bai, Hao Ai, Jen-Yuan Huang, Zechao Li NeurIPS, 2025 arxiv / demo / website / code In this work, we devlop an image stylization model named CSGO, which transfers the style presented by an input reference image to a source image. To enable end-to-end training, we introduce an automatic construction pipeline and IMAGStyle, first large-scale style transfer dataset with 210K {content;style;target}-triplet. |
|
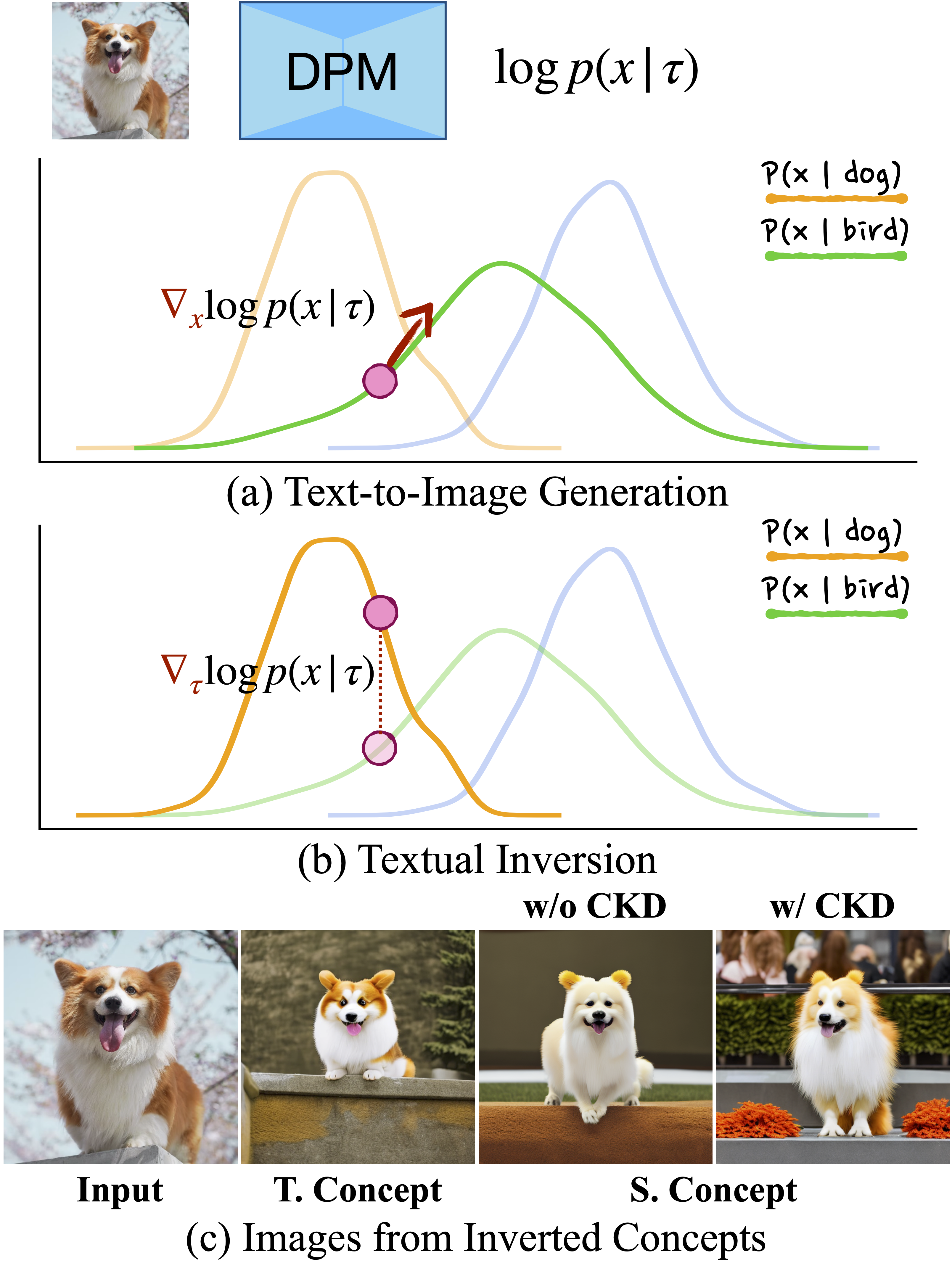
Remedy Text-to-image Diffusion Model Compression via Concept Knowledge DistillationJen-Yuan Huang, Jen-Tse Huang, Huan Wang, Tong Lin work in process, 2025 We identify the performance degradation in textual-inversion of T2I diffusion models after compression. By reformuolating the concept discovery process like textual-inversion as an implicit text generation model’s inference, we propose to a knowledge-distillation based retraining method via aligning gradients with respect to text condition. |

|
InstantStyle-Plus: Style Transfer with Content-Preserving in Text-to-Image GenerationHaofan Wang, Peng Xing, Jen-Yuan Huang, Hao Ai, Qixun Wang, Xu Bai arXiv, 2024 arxiv / demo / website / code In this paper, we explore natural style transfer while maintaining content integrity. Through analyzing different components of the Stable Diffusion UNet, we identify layers that specialize in processing style and content. Furthermore, we introduce a style discriminator to enhance the stylization of the output. |
Contact |
|
|
E-mail: jenyuan@stu.pku.edu.cn |
|